Język C: Czasochłonne błędy przez które ludzie programiści skaczą z mostów – część 1
Wed, 15 February 2017
Niniejszym rozpoczynam cykl artykułów o niezwykle czasochłonnych błędach programistycznych z którymi osobiście się spotkałem/ które osobiście popełniłem. W niniejszym cyklu chciałbym uchwycić to, jak malutki szczegół, czasem choćby jedna zła literka w kodzie może doprowadzić do potężnego błędu unieruchamiającego całe oprogramowanie lub powodującego krytyczne błędy bezpieczeństwa (w dzisiejszym odcinku będzie też o nich).
Wyłuskane przykłady starałem się możliwie jak najbardziej ociosać ze zbędnych fragmentów kodu, tak aby przedstawić samo sedno problemu. Zanim powie się „Oh… jakie łatwe” trzeba zdać sobie sprawę, że kod taki nie pracował w takiej formie jak został tutaj przedstawiony (a więc z czytelnym wejściem, czytelnym wyjściem i wizualizacją tego co się dzieje).
Najgorszym w tego typu błędach jest właśnie to, że taki kod działa często gdzieś w środku programu i tylko czasami zaburza jego działanie, przez większość czasu spoczywając w uśpieniu. Często programiści mogą pomarzyć o tak czytelnym przedstawieniu sytuacji jak w poniższych listingach. Czasami również nie mają w ogóle możliwości wypisania danych na ekran, bo takiego ekranu po prostu nie ma (poniższy błąd odkryłem w jednym z programów na malutkie mikrokontrolery, bez podłączonego wyświetlacza, bez portu szeregowego, z jedynym wyjściem w postaci diody LED, za pomocą której debugowało się program).
Wstęp
Zacznijmy więc cykl od programu, który nagle zaczyna działać po przeniesieniu deklaracji zmiennej do innej linijki, albo po zakomentowaniu deklaracji zmiennej, która w ogóle nie jest używana (!). Weźmy na warsztat kod. Dość ciekawy, ponieważ występuje w nim coś więcej niż tylko tajemnicze zachowanie się programu:
#include <stdio.h>
typedef unsigned char uint8_t;
int main()
{
printf("Podaj liczbe mieszczaca sie w przedziale 0-255: ");
uint8_t storedNumber1 = 15;
uint8_t userNumber;
uint8_t storedNumber2 = 33;
char format[] = "%d";
scanf(format, &userNumber);
printf("Wprowadzona liczba to: %d\n", (int)userNumber);
printf("storedNumber1: %d\n", (int)storedNumber1);
printf("storedNumber2: %d\n", (int)storedNumber2);
return 0;
}
Jak widać, prosimy użytkownika o wprowadzenie liczby z przedziału 0-255 (dla uproszczenia przykładu ufamy
użytkownikowi, że wprowadzi liczbę właśnie z tego zakresu). Aby oszczędzać pamięć deklarujemy sobie nawet specjalny
typ danych mogący przechowywać właśnie dokładnie 1 bajt (a więc zakres 0-255), bez znaku. Następnie zapamiętujemy
dwie dodatkowe liczby (które są wprowadzone w programie), wczytujemy liczbę wprowadzoną przez użytkownika, a
następnie wypisujemy wszystkie liczby na ekran. Niby proste zadanie, prawda? Ale niekoniecznie. I w tak prostym
programie może kryć się kilka błędów. Ja chciałbym opowiedzieć (na jego przykładzie) o kilku najtrudniejszych do
wytropienia.
Na pierwszy rzut oka, na ekranie powinny pojawić się następujące liczby:
<liczba wprowadzona przez użytkownika> 15 33Kiedy jednak uruchomimy taki program, spostrzeżemy, że na ekranie wyświetliło się:
<liczba wprowadzona przez użytkownika> 0 0Na dodatek, chcąc wytropić błąd, wkrótce odkryjemy, że kiedy przesuniemy linijkę z deklaracją zmiennej format, na sam początek programu, w ten sposób:
#include <stdio.h>
typedef unsigned char uint8_t;
int main()
{
printf("Podaj liczbe mieszczaca sie w przedziale 0-255: ");
char format[] = "%d"; // linijka przesunięta na początek
uint8_t storedNumber1 = 15;
uint8_t userNumber;
uint8_t storedNumber2 = 33;
scanf(format, &userNumber);
printf("Wprowadzona liczba to: %d\n", (int)userNumber);
printf("storedNumber1: %d\n", (int)storedNumber1);
printf("storedNumber2: %d\n", (int)storedNumber2);
return 0;
}
… wówczas program działa poprawnie. Co tu jest grane? Wystarczy przesunąć deklarację zmiennej aby
program ruszył? Ki czort?
Smaczku doda jeszcze fakt, że gdy zmienimy deklarację naszego typu dodając modyfikator „volatile”,
wówczas program będzie działał w połowie poprawnie, wyświetlając tylko jedną z wpisanych w programie liczb (33).
typedef volatile unsigned char uint8_t;
W takim przypadku wynik działania programu będzie następujący:
<liczba wprowadzona przez użytkownika> 0 33Dla tych, którzy pierwszy raz spotykają się z modyfikatorem volatile omówię pokrótce jego działanie. Volatile sprawia jedno - kompilator nie optymalizuje danej zmiennej. Przez co, na przykład, procesor nie przechowuje jej w jednym ze swoich rejestrów w celu przyspieszenia obliczeń, tylko za każdym razem sięga po nią do pamięci RAM. Modyfikator volatile niezwykle przydaje się gdy pracujemy z programami opartymi o przerwania (prawie wszystkie programy na systemy wbudowane oparte na mikrokontrolerach). Wówczas jeśli mamy zmienną zadeklarowaną z pominięciem volatile i przypiszemy do niej wartość np. 22, następnie wykona się przerwanie w którym wartość zmiennej zostanie zmodyfikowana na 17 to po zakończeniu przerwania (powrocie do głównego programu) i próbie odczytania tej zmiennej, nadal czasami dostaniemy 22, bo procesor gdzieś ją tam jeszcze przechowuje w swoich podręcznych rejestrach, aby nie sięgać po nią do RAMu za każdym razem.
Dlatego jeśli chodzi o takie, trudne do wykrycia błędy jak te właśnie omawiane, polecam stosowanie volatile, aby dodatkowo nie komplikować sobie rozwiązywanego problemu nieaktualnymi wartościami zmiennych, które mogą się przydarzyć.
Jak to wygląda na niskim poziomie?
Zobaczmy zatem jak kod programu wygląda niskopoziomowo, w Assemblerze: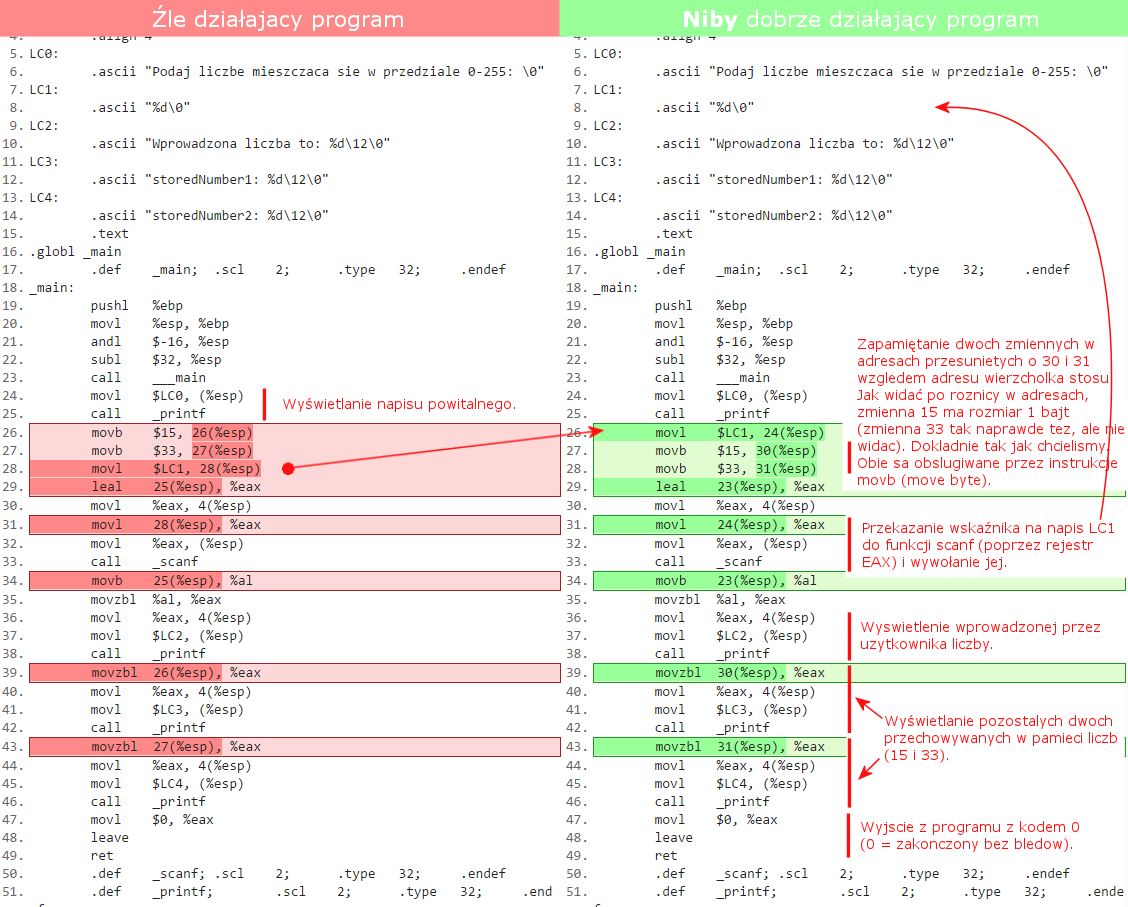
Jak widać różnice pomiędzy programami odpowiadającymi Listingowi 1 (po lewej) i Listingowi 2 (po
prawej) są zauważalne, jednak nie widać tam nic niezwykłego. Zwykłe odkładanie argumentów na stos i
wywoływanie funkcji.
No dobrze więc - powiecie - być może błąd jest w tych wywoływanych funkcjach? Oczywiście chciałoby się zwalić
winę na funkcje zawarte w bibliotece <stdio>, ale nie. One błędnie działają, ponieważ dostają błędne dane. Błąd jest u nas. A dokładnie w
łańcuchu „%d” na który wskazuje zmienna format. Łańcuch ten „mówi” funkcji scanf, że zmienna
(przekazana przez referencję) do której ma wpisać wprowadzoną przez użytkownika wartość może
pomieścić typ signed integer (%d = signed integer, który ma długość 4 bajtów). Tymczasem nasza
1-bajtowa zmienna nie może pomieścić aż tylu danych, więc program nadpisuje zerami (bo 3 z 4
bajtów będą zerowe w przypadku wprowadzenia wartości z zakresu 0-255) zmienne leżące bezpośrednio nad naszą zmienną.
Błąd ten pojawił się w
oprogramowaniu, które pisałem na 8-bitowy procesor. W większości kompilatorów na 8-bitowe
procesory, zmienna int nie jest wcale 8 bitowa (jak może mogłoby się wydawać), ale 16-bitowa (wynika te ze standardu C99). Co
ciekawe, wpisanie jako parametr funkcji scanf ciągu „%hhu” odpowiadającego właśnie (już
prawidłowo) typowi „unsigned char” nie zmienia sytuacji w kompilatorze GCC MinGW pod Windows (korzystam z wersji 4.4.1) i Cygwin. Wpadłem na to gdy zacząłem grzebać z ciekawości. O tym, dlaczego tak się dzieje już napisałem kolejny artykuł.
No dobrze, powiecie, ale o ile kompilator faktycznie nie wyświetla ostrzeżeń związanych z podaniem mu modyfikatorów formatu, których nie obsługuje (jak %hhu), to przecież wyświetla ostrzeżenia w przypadku podania do
funkcji scanf zmiennych o typie innym niż podane doń parametry.

Tak! Jest to prawda, tylko pod warunkiem, że format wprowadzamy jako literał:
scanf(„%d”, &userNumber);
Jeśli format jest zmienną (w naszym przypadku wskaźnikiem na ciąg znaków) to kompilator już
ostrzeżenia nie pokaże.
Ale wróćmy jeszcze do tych nadpisywanych zmiennych. To, że zmienne poprzedzające w deklaracji zmienną userNumber zostają nadpisane dobrze widać na kolejnym listingu:
#include <stdio.h>
typedef volatile unsigned char uint8_t;
int main()
{
printf("Podaj liczbe mieszczaca sie w przedziale 0-255: ");
uint8_t storedNumber1 = 15;
uint8_t storedNumber2 = 33; // zostanie nadpisana
uint8_t storedNumber3 = 55; // zostanie nadpisana
uint8_t storedNumber4 = 77; // zostanie nadpisana
uint8_t userNumber; // zostanie nadpisana (tutaj akurat tego chcemy)
char format[] = "%d";
scanf(format, &userNumber);
printf("storedNumber1: %d\n", (int)storedNumber1);
printf("storedNumber2: %d\n", (int)storedNumber2);
printf("storedNumber3: %d\n", (int)storedNumber3);
printf("storedNumber4: %d\n", (int)storedNumber4);
printf("Wprowadzona liczba to: %d\n", (int)userNumber);
return 0;
}
Podaj liczbe mieszczaca sie w przedziale 0-255: <liczba wprowadzona przez użytkownika> storedNumber1: 15 storedNumber2: 0 storedNumber3: 0 storedNumber4: 0 Wprowadzona liczba to: <liczba wprowadzona przez użytkownika>
Jak widzimy, trzy kolejne 1-bajtowe zmienne mają wartość 0. Wliczając w to zmienną do której wprowadzaliśmy wartość pobraną od użytkownika mamy 4, 1-bajtowe zmienne, czyli dokładnie taki rozmiar jaki zajmuje zmienna typu integer (4 bajty). Funkcja scanf nadpisała nam więc 4 kolejne zmienne, zamiast jednej. Jeśli użytkownik podał przykładowo do programu liczbę 24, nasze 4 zmienne zostały po prostu nadpisane wartością 0x00000018 (18 w systemie szesnastkowym to 24 w systemie dziesiętnym). Jest to typ błędów określanych jako integer overflow.
Co by się stało jednak, gdybyśmy do programu wprowadzili liczbę spoza zakresu zmiennej userNumber? W normalnym przypadku (gdyby funkcja sscanf wczytywała 1 bajtową zmienną zamiast 4 bajtowej), licznik by się przekręcił. I tak, wpisując wtedy np. 258, otrzymalibyśmy w zmiennej userNumber liczbę 2:
255 -> 255
256 -> 0
257 -> 1
258 -> 2
A jak będzie w naszym przypadku? Spróbujmy wprowadzić do programu liczbę 1234567890. Akurat tak się szczęśliwie składa, że liczba 1234567890 zajmuje nam wszystkie 4 bajty zmiennej typu integer w 32-bitowych systemach (standard C99 odnoszący się do języka C definiuje jedynie, że zmienna int ma mieć przynajmniej 16 bitów, na codzień przy programowaniu komputerów spotykamy się z 32-bitowymi zmiennymi typu integer). Spójrzmy na jej reprezentację binarną:
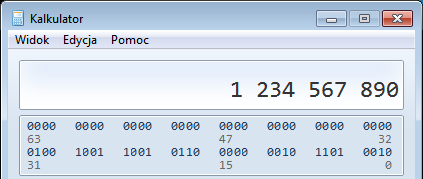
Gdyby więc pociachać naszą 4 bajtową liczbę typu integer na 1 bajtowe kawałki, otrzymalibyśmy:
01001001 = 73
10010110 = 150
00000010 = 2
11010010 = 210
Co więc wydarzy się gdy użytkownik wprowadzi do programu liczbę 1234567890? Nasze "1 bajtowe kawałki" znajdą się w kolejnych zmiennych, pod kolejnymi adresami w pamięci:
Podaj liczbe mieszczaca sie w przedziale 0-255: 1234567890 storedNumber1: 15 // nienadpisana storedNumber2: 73 storedNumber3: 150 storedNumber4: 2 Wprowadzona liczba to: 210
Kwestie bezpieczeństwa
A jak to jest z bezpieczeństwem aplikacji, które zawierają tego typu błędy? Nietrudno sobie wyobrazić scenariusz, w którym ktoś specjalnie przekracza zakres zmiennej, aby wymusić nadpisanie innej zmiennej, która w odpowiedni sposób zmieni działanie programu (np. da dostęp do tajnych danych).
Zobaczmy sobie taki przykład:
#include <stdio.h>
typedef volatile unsigned char uint8_t;
int main()
{
printf("Podaj liczbe mieszczaca sie w przedziale 0-255: ");
bool allowAccess = false;
uint8_t userNumber;
char format[] = "%d";
scanf(format, &userNumber);
if (allowAccess)
{
printf("Zezwolono na dostep do tajnych danych: Lech Walesa to Bolek\n");
}
printf("Wprowadzona liczba to: %d\n", (int)userNumber);
return 0;
}
Jak widzimy, zmienna allowAccess jest ustawiona na false, a nigdzie dalej nie zmieniamy explicite (jawnie) jej wartości na true.
Tajne dane nigdy nie powinny więc zostać wyświetlone (i tak będzie dopóki będziemy grzecznie wprowadzać wartość z określonego zakresu). Co się stanie jednak, gdy "przepełnimy" naszą zmienną userNumber tak aby zmienna allowAccess została nadpisana dowolną, niezerową liczbą (zmienna zostanie potraktowana przez procesor jako true kiedy będzie w niej dowolna wartość nie będąca zerem).
Spróbujmy się zatem włamać do programu tak, aby uzyskać tajne dane. W tym celu uruchamiamy program i - zapytani - wprowadźmy dowolną liczbę, która nie zmieści się w jednym bajcie - np. 256. Wynik działania programu będzie następujący:
Podaj liczbe mieszczaca sie w przedziale 0-255: 256 Zezwolono na dostep do tajnych danych: Lech Walesa to Bolek Wprowadzona liczba to: 0Przez odpowiednie machinacje na danych wejściowych, uzyskaliśmy dostęp do tajnych danych, do których nigdy nie powinniśmy mieć dostępu.
Czy istnieje mechanizm zapobiegania błędom typu integer overflow w języku C?
Niektóre języki (np. Delphi, Java) posiadają wewnętrzne zabezpieczenia przeciwdziałające tego typu błędom (tzw. Run-time overflow detection). Kompilator GCC jednak domyślnie nie posiada włączonych tego typu mechanizmów. Możemy co prawda próbować z następującymi flagami kompilatora:
gcc c:\main.cpp -o c:\main.exe -fstrict-overflow -fwrapv -ftrapvJednak one dotyczą trochę innej rzeczy - przepełniania zmiennych ze znakiem (signed integers), zwłaszcza w przypadkach kiedy wychodzimy poza ich zakres wykonując na nich operacje np. mnożenia. W naszym przypadku nie pomoże to wcale.
Co z mechanizmami typu DEP, NX-bit?
One po prostu nie mają zastosowania do tego typu przypadków. Chronią przed innymi rzeczami - przed wykonaniem danych. Zabezpieczają więc dane wprowadzane przez użytkownika do programu tak, aby procesor nie potraktował ich jako instrukcje do wykonania.Dlaczego bajty nadpisywane są w tę, a nie drugą stronę?
Pewnie zastanawiacie się teraz dlaczego procesor nadpisuje dane w pamięci w tę, a nie w przeciwną stronę? Spójrzmy najpierw jaka kolejność tak naprawdę obowiązuje u nas. Zmodyfikowałem nasz program tak, aby pokazywał adresy wszystkich naszych zmiennych:
#include <stdio.h>
typedef volatile unsigned char uint8_t;
int main()
{
printf("Podaj liczbe mieszczaca sie w przedziale 0-255: ");
uint8_t storedNumber1 = 15;
uint8_t storedNumber2 = 33;
uint8_t storedNumber3 = 55;
uint8_t storedNumber4 = 77;
uint8_t userNumber;
char format[] = "%d";
scanf(format, &userNumber);
printf("Adres storedNumber1: %x\n", &storedNumber1);
printf("Adres storedNumber2: %x\n", &storedNumber2);
printf("Adres storedNumber3: %x\n", &storedNumber3);
printf("Adres storedNumber4: %x\n", &storedNumber4);
printf("Adres wprowadzonej liczby to: %x\n", &userNumber);
return 0;
}
Adres storedNumber1: 28ff1b Adres storedNumber2: 28ff1a Adres storedNumber3: 28ff19 Adres storedNumber4: 28ff18 Adres wprowadzonej liczby to: 28ff17Widzimy zatem, że zmienna zadeklarowana najpóźniej (`userNumber`) ma najniższy adres (adresowanie odbywa się zatem od szczytu pamięci do dołu). Kierunek nadpisywania danych to cecha danej architektury procesora. Na tym przykładzie bardzo dobrze widać jak zachowują się procesory little endian (tak więc wszystkie procesory x86) – zapisują one najmniej znaczące bajty zaraz na początku, w najniższych adresach, a najbardziej znaczące bajty w najwyższych adresach danej zmiennej. Więcej o tej właściwości procesorów można poczytać na Wikipedii.
Zakończenie
Mam nadzieję, ża artykuł okazał się ciekawy. Starałem się jak najgłębiej wejść w problem, tak aby nie pozostała żadna niejasność. Być może niektórzy z Was dowiedzieli się przy okazji czegoś nowego.









Podobne artykuly:
- [microC, AVR] Użycie sprintf wyrzuca błędy kompilacji - o co chodzi?
- [microC, AVR] Jak zwiększyć wydajność pętli?
- [microC, AVR] Jak wykonać kod jeszcze przed wejściem w main()?
- Podczas kompilacji dowolnego projektu w Android Studio wywala błąd "Gradle sync failed: Cause: com/sun/org/apache/xerces/internal/impl/XMLEntityManager" - co jest nie tak?
- Dostałem podziękowanie od Embarcadero/Borland za zgłoszony błąd